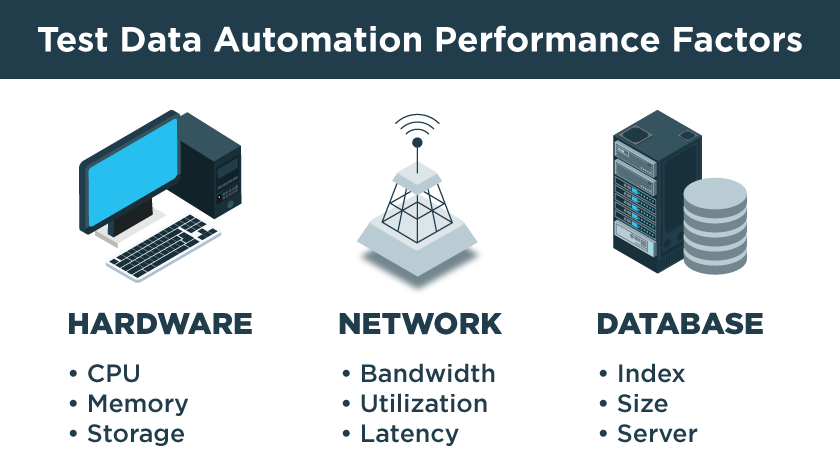
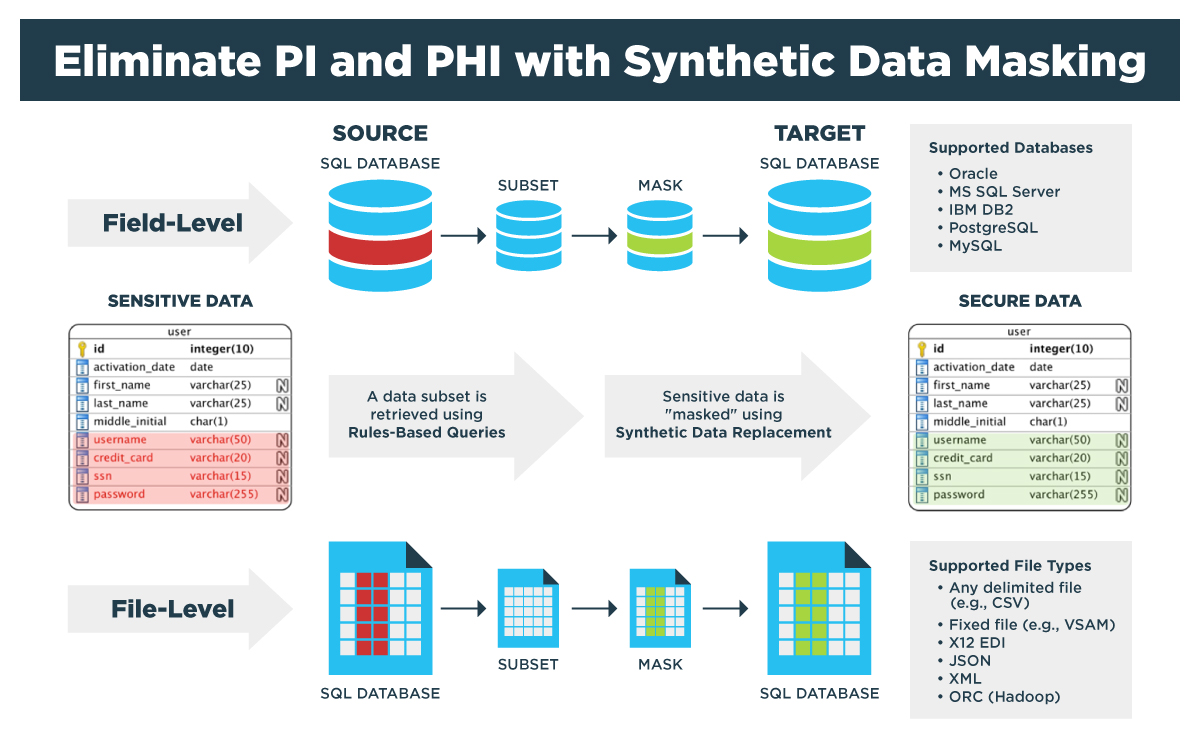
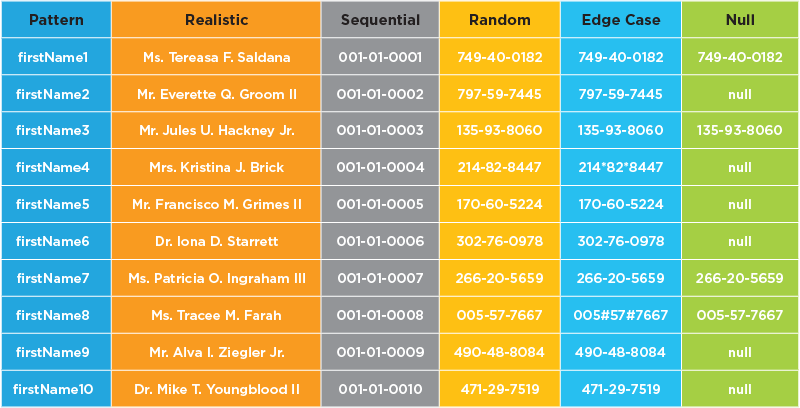
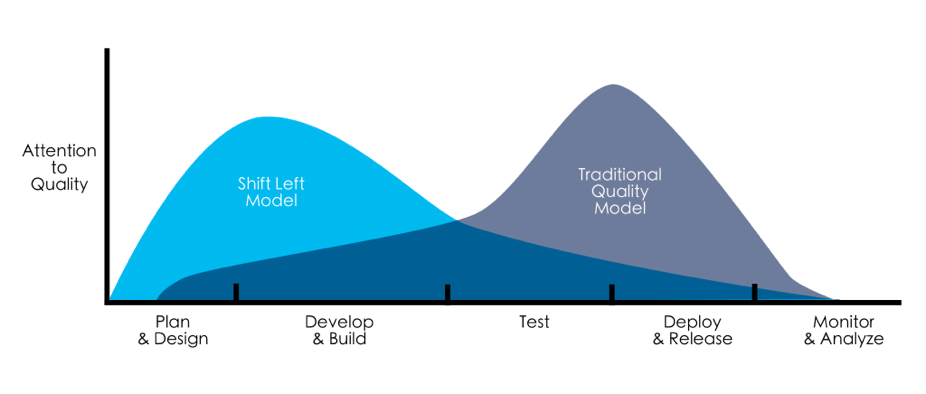
Some analysts believe that the market for machine learning may surpass $9 Billon USD this year. The surge in growth in the ML market is exponential as new avenues for software development and applications emerge. With this surge in new applications comes the need for massive volumes of data to train ML models to perform at a high level of accuracy and consistency. Here, we present an overview of the role synthetic data can play in training machine learning algorithms. And we’ll identify the best applications for GenRocket’s Synthetic Test Data Automation platform in this rapidly growing industry.