Debunking 3 Myths About Software Test Data

Quality Assurance is also an exciting place to be with the arrival of shiny new test automation tools and frameworks that promise to simplify and streamline the rigors of manual testing, allowing testers to keep pace with the speed of development.
However, the test data needed for the software testing automation tools is often considered to be something of a third wheel in the relationship between developers and testers. It just doesn’t get the attention it deserves.
When you think about it, test data is critically important to the success of Continuous Testing, Integration and Delivery of enterprise software. After all, if test data does not exercise the software under test in all the right ways, bugs happen.
In this article, we are going to talk about what test data should be, and should not be, as a critical success factor for the practice of software quality assurance. We are also going to debunk 3 myths about test data running rampant in the software industry. They relate to whether the test data you are using is copied from a production database or generated as
synthetic test data to replicate production data.
Myth #1: Synthetic Test Data is Random Data
Many QA professionals are under the mistaken impression that synthetic data is simply randomized data, properly formatted for field types, field length and number of rows, but with randomized values. This perception was spawned by the availability of open source test data generators that offered a quick, easy and inexpensive path to provisioning synthetic test data. This is an example of what test data should not be.
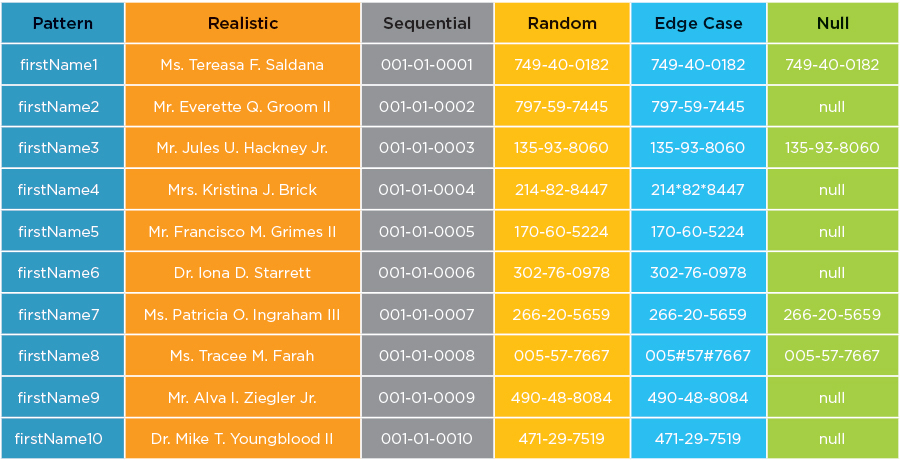
For most test cases, synthetic test data can and should be the opposite of randomized data. Test data should be accurate and conditioned to represent the data patterns needed for each test case (positive or negative). The image below is an example of six different synthetic test data design patterns, which can include randomized or realistic data if required.
Myth #2: Production Data is Higher Quality than Synthetic Test Data
A second misconception is that production data must be higher quality than synthetic test data because it is real data from an operational environment. However, the drawback of using production data for test data comes back to the issue of control. When you copy a subset of data from a production database, what you get is what you get. There is no control over the
nature of the data in terms of its required data values and variations.
In a test environment, it is important to control the patterns and permutations of data for testing a variety of edge case and boundary conditions. Highly controlled test data helps to minimize false negatives (when good code fails an assertion test) and false positives (when bad code passes an assertion test). Synthetic test data can be configured for any and all of these conditions and generated in sufficient volume to maximize code coverage.
Myth #3: Masked Production Data is Secure Data
Many quality assurance professionals are operating under the mistaken impression that when they mask production data, they are fully protecting their employer from an unintended breach of Personally Identifiable Information (PII). To begin with, masking all sensitive components of a production database is very difficult to do while preserving referential integrity between data tables. And once masked, private patient or customer data can still be compromised by piecing together clues from other data elements. One researcher found that 87 percent of Americans could be identified by three unique identifiers: their date of birth, gender and zip code. Masking data does not eliminate all of the clues that can be used to identify the original owner of private information.
Additionally, masking does not alleviate the risk of PII being compromised by an insider, the type of security threat that represents a large percentage of data breaches. And for many QA operations, testing functions are often outsourced to an external resource, further limiting organizational control. As soon as production data leaves the production environment, it poses a significant risk to the organization in the form of fines, penalties and loss of good will. Synthetic test data, by definition, is artificial data and offers the only way to completely eliminate the security risks associated with using sensitive production data.
So here is the good news for testers. They now have a shiny new technology for generating accurate, patterned, conditioned and controlled test data on-demand with a Test Data Generation (TDG) platform. The leading platform in this space is GenRocket TDG, an enterprise test data solution that generates any kind of test data imaginable based on your database schema and a test data scenario. The test data scenario specifies the specific variations and volume of data needed by a given test case, be it functional, integration, performance, or regression testing. Synthetic test data is generated according to these controlled specifications at the rate of 10,000 rows per second.
Together, continuous delivery pipelines (e.g., Jenkins), test automation tools (e.g., Selenium) and test data generation platforms (e.g., GenRocket TDG) represent essential elements of a technology stack designed for the age of Agile, DevOps and Continuous Delivery. Here is a link to learn more about how real-time synthetic test data can be use for optimizing test automation for continuous delivery.