Data Modeling and Referential Integrity
Part 2 in the series: Moving from Test Automation to Intelligent Automation
In part 1 of this series, we introduced the concept of Intelligent Data Provisioning – the ability to design and generate test data on-demand using a flexible self-service framework. It’s the future of traditional Test Data Management and essential for ensuring quality at speed in DevOps and Agile environments.
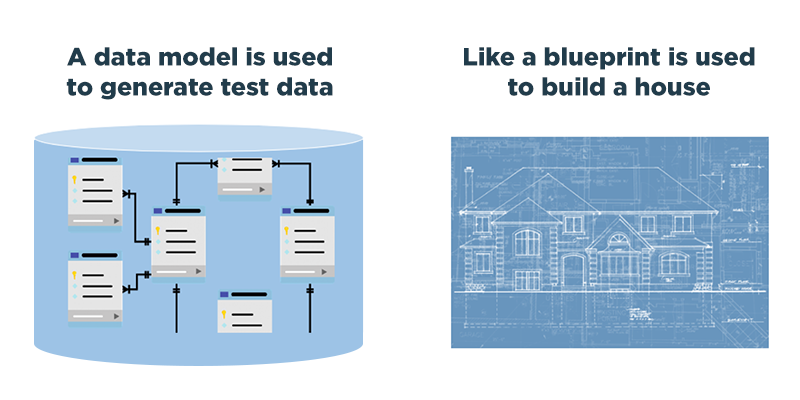
To ensure the validity of synthetic data designed to replicate a production database, it’s crucial to maintain the integrity of its data structure. Data structure is defined by a database schema or Data Definition Language (DDL) and serves as the blueprint for generating real-time synthetic test data. With GenRocket’s Test Data Automation (TDA) platform, a QA team member imports the data model into the TDA platform. Then with the help of an intelligent wizard, all parent/child/sibling relationships are reviewed, refined and established as GenRocket Domains for use with any Test Data Scenario.
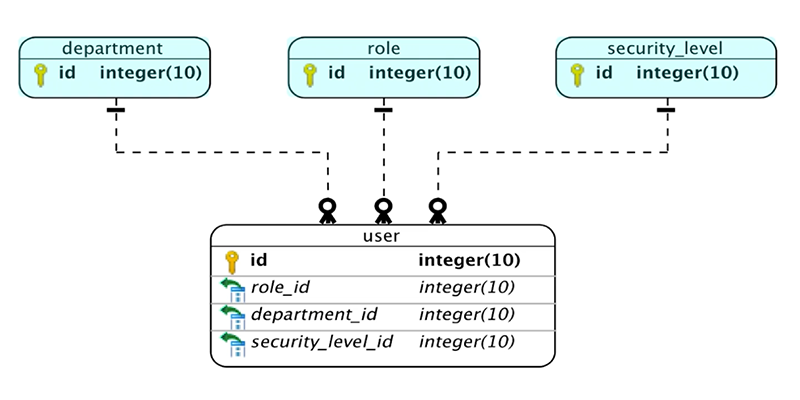
The concept of referential integrity is illustrated in the ER diagram below. An employee database with a user data table contains key pairs that relate the department, role and security-level tables. The parent table contains the primary key and its child or sibling tables contain foreign keys. Together, they define the relationships between data tables.
Generating Model-Based Test Data
Once imported and validated, the data model allows QA teams to generate test data for any category of testing. This allows rapid provisioning of data for both functional and non-functional tests by applying rules that define the volume and variety of data needed to meet test case objectives. GenRocket’s component architecture and project dashboard make it easy to design and configure the precise test data needed for testing in a matter of minutes.
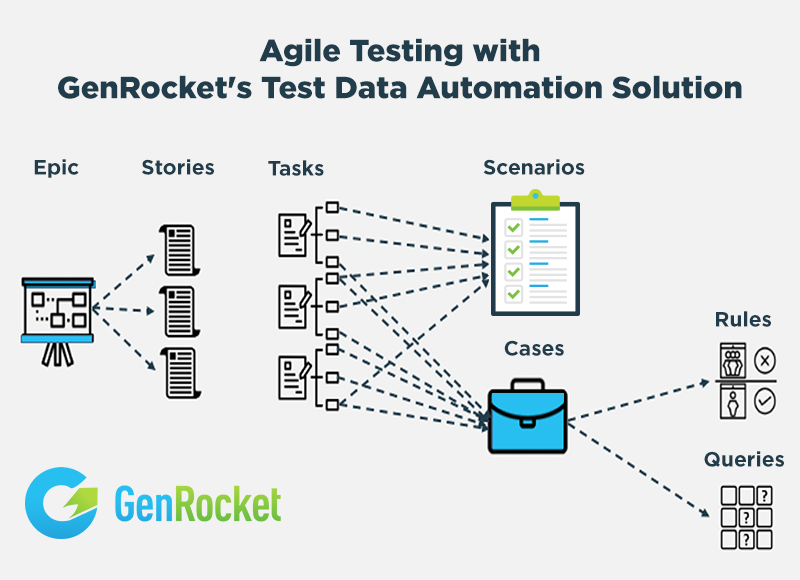
GenRocket stores Test Data Scenarios and Test Data Cases in a repository that is shared by the QA team. Scenarios and Cases can be repurposed as needed and version-controlled for automated regression testing on multiple versions of code. Each time a Test Data Scenario or Test Data Case is invoked by a test procedure, a fresh copy of data is generated. This allows destructive testing procedures without altering the original state of the test dataset and eliminates the need for data refresh.
Here is a summary of the steps followed in GenRocket’s Test Data Automation process:
- Determine all data sources and formats for the application under test
- Import the data model or DDL for those data sources and validate referential integrity
- Define the test data requirements for each test case at the Agile Story level
- Create executable Test Data Scenarios and Test Data Cases using GenRocket’s self-service dashboard
- Automate test procedures and invoke Test Data Scenarios and Test Data Cases during test execution
- Store, repurpose and manage Test Data Scenarios and Test Data Cases throughout the testing lifecycle
GenRocket’s intelligent test data provisioning platform elevates test automation to become intelligent automation enabling QA to keep pace with Agile and DevOps environments while improving the quality of code released to production.
Importing a Data Model into GenRocket
GenRocket has designed multiple ways to import a data model into the GenRocket TDA platform and control the referential integrity of data relationships. This is to accommodate QA teams that may not have access to database schema. Additionally, some databases are poorly normalized and lack good referential integrity. And in some cases, a data model simply does not exist before newly developed code is implemented.
Here are four different methods to import a data model into GenRocket:
- DDL File Import
- Extract Table Schema (XTS)
- CSV File Import
- Manually with a Scratch Pad
You can learn how to use each of these methods, by reading this knowledgebase article.
In the GenRocket component architecture, each data table is represented as a Domain. Testers can quickly change Domain parent, child and sibling relationships to produce the type of data they need and to maintain the referential integrity of generated data.
Database schemas are constantly evolving and GenRocket was designed with this in mind. Even when a schema is not finalized for testing a user story, testers can change their GenRocket Domains to reflect the latest version and the system will automatically restructure existing Scenarios to match re-defined Domain relationships. This process is referred to as Domain Auto-Refactoring.
For a detailed description of how GenRocket can work with multiple database environments, read the knowledgebase article How GenRocket Works with Databases.
Modeling a Database Environment – One Domain at a Time
GenRocket allows testers, quality engineers and developers to import any data model and immediately begin to design and generate test data. While the process is streamlined by an intuitive user interface and assisted by intelligent automation, modeling a large-scale enterprise database with hundreds of tables can take time.
It’s important to understand that only those tables (i.e., Domains) needed for a given test case should be modeled and designed into a Test Data Scenario, not the entire database schema. The most efficient way to model a database is by defining one Domain at a time, based on test data requirements.
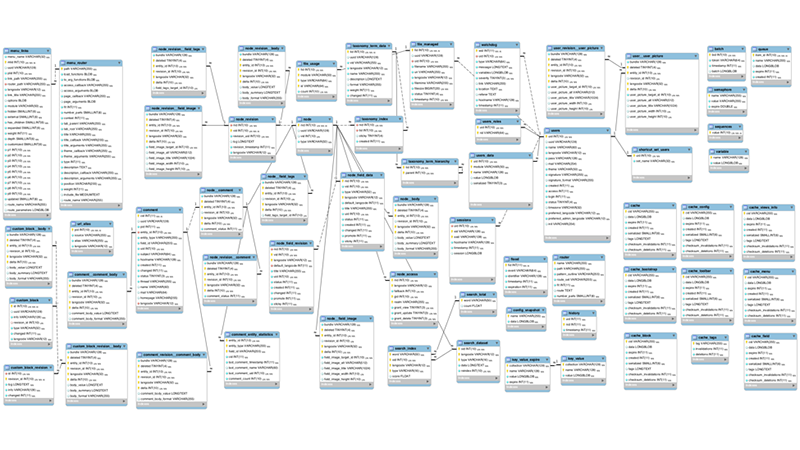
Consider the following database schema diagram showing 60 tables. Now imagine an application that needs to access several databases of similar size and scope. It’s not required, or even recommended, that the QA team define the hundreds of data tables potentially touched by this application prior to executing a test plan.

To see GenRocket’s Test Data Automation technology in action, view a banking solutions video in which GenRocket CTO Hycel Taylor demonstrates the power of intelligent test data provisioning.