Moving from Test Automation to Intelligent Automation
Part 1: Making the case for intelligent test data provisioning
Automated testing has become essential technology for Continuous Integration and Continuous Delivery. For QA teams to achieve the ultimate goal of quality at speed, the intelligent use of automation must play a significant role at each level of the Agile software testing pyramid.
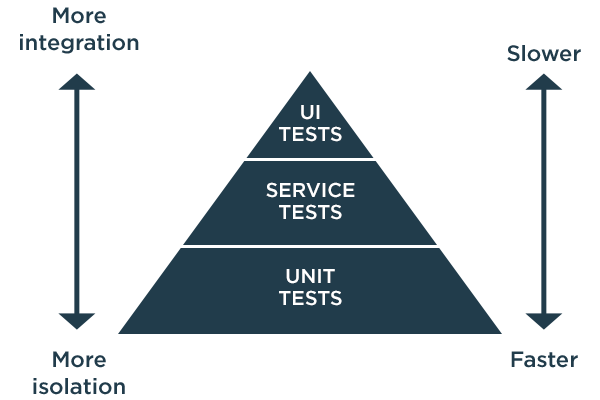
Unit tests are low-hanging fruit for test automation. They represent the highest number of tests and they are the easiest to automate. Service level tests are integration tests performed on two or more units of code to validate functional and non-functional QA requirements. Automation at this level requires more formalized test plans.
UI testing is where complex End-to-End (E2E) tests are conducted to ensure the business logic of an application is sound and user expectations are fully met. To automate E2E testing, complex workflows and data interactions must be understood and subjected to a rigorous suite of positive and negative test cases.
Each level of testing requires different classes of test data to meet their objectives.
Unit Level Test Data Requirements
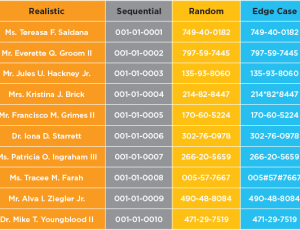
Unit testing requires a precise subset of data for testing the methods and behaviors of an individual unit of code. Test data should provide the combinations, patterns and permutations needed to validate assertions, test edge cases, and quickly identify defects. Unit testing can be performed by developers or QA engineers who need test data at a moment’s notice.
Service Level Test Data Requirements
The service level involves integration testing that requires more elaborate test data to simulate real-world database interactions and data exchanges between application program interfaces (APIs). This level of testing relies on controlled, accurate and realistic data to test transaction processing, data interface compatibility, data security provisions, and the performance of integrated software under varying load conditions. Automating the service level enables more complete testing with greater code coverage and at higher velocity.
UI Level Test Data Requirements
At the UI testing level, end-to-end, or E2E system testing is performed. While E2E testing represents the lowest volume of tests, they are the most complex. When testing is fully automated at the lower levels, E2E testing can be conducted on code that has fewer errors. This allows testers to focus on business solutions that provide a positive end user experience. Provisioning test data for E2E testing is demanding and requires highly controlled data variations, often in high volume and using multiple database formats. Successfully automating this level greatly reduces the time required to execute a comprehensive end-to-end test plan.
Traditional Test Data Provisioning – Sacrificing Quality for Speed
Most QA organizations provision data for test automation in one of 3 ways:
- Through the use of a Test Data Management (TDM) system
- By manually creating test data in the form of Excel spreadsheets
- A combination – by manually modifying production data provisioned by a TDM system
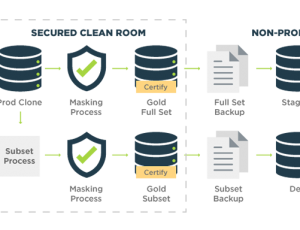
TDM systems are costly and complex to operate. They require members of the QA staff to be trained and dedicated to a centralized data provisioning function. Testers must requisition test data, wait for it to be copied from production, subsetted for their testing purposes and anonymized to remove sensitive data. It’s a cumbersome process with turnaround times that are usually measured in days or even weeks.
Centralized TDM fails to provide testers with the variety, volume and validity of data needed for comprehensive testing. A copied subset of production data offers no control over the data combinations, patterns or permutations. Testers simply get data that happens to be in the dataset that was copied and anonymized. This makes thorough testing of edge cases, boundary conditions, or negative testing scenarios virtually impossible.

With manual test data provisioning, testers create the data they need using Excel spreadsheets where database tables are recreated with columns and rows. Manual test data creation is labor intensive and highly complex if the tester attempts to maintain referential integrity. Manual creation robs testers of valuable time needed for developing and executing new test procedures. And because test data is created by hand, it limits the volume and variety of test data available for testing.
When test data is provisioned either manually or with a centralized TDM, data quality is sacrificed to avoid delays in the testing process and the impact on the software release cycle.
Intelligent Test Data Provisioning
Test automation succeeds because it leverages technology to perform repetitive procedures at high speed and without human intervention. While human intelligence is needed to design the test procedure, once they are configured, tests can be run at high speed and on a predefined schedule for as long, or as often, as required.
Test data provisioning must benefit from the same level of automation as test operations.
GenRocket’s concept of Test Data Automation (TDA) brings intelligence to the test data provisioning process. In place of the high-touch approach required by TDM systems and manually created spreadsheets, TDA uses a platform for Intelligent Test Data Provisioning.
This approach replaces the human intervention required by TDM and manual test data provisioning with intelligent automation. GenRocket’s TDA platform is architected with intelligent components that put control over data quality in the hands of the tester.
Here are 10 guiding principles of GenRocket’s TDA platform:
- The variety, volume and validity of test data is under the complete control of testers
- Test data is designed and configured to meet the requirements of each test case
- Test Data Scenarios contain instructions for real-time synthetic test data generation
- Test Data Generators have the intelligence to create any variation of test data
- Test Data Receivers have the intelligence to produce data in any format
- Test Data Domains and Attributes follow a data model to ensure referential integrity
- The GenRocket Ecosystem enables secure, on-demand self-service provisioning
- Synthetic test data is 100% secure and guarantees compliance with privacy laws
- Synthetic test data can be blended with production data to ensure validity
- Test data configurations are designed for collaboration and lifecycle management
Here’s an example. A tester needs data to validate the accuracy of transaction processing code in a newly developed software module. The test procedure requires the use real and accurate account numbers for all major credit cards. It also requires an authentic customer ID to be associated with the purchase and the calculation of total purchase, sales tax and reward points.
Previously, the tester would request test data from a centralized provisioning team or create the data manually in a spreadsheet. However, with the use of GenRocket’s TDA platform, testers can now generate controlled, accurate test data in real-time and on-demand.
With GenRocket, a test data configuration file (i.e., Test Data Scenario) can be created based on the schema or DDL for the production database and use intelligent data generators to produce real credit card account numbers. These account numbers are real, but they are synthetically produced and not associated with the actual account holder in any way. They can be generated in any pattern and include null data and invalid or incomplete account numbers to maximize the coverage of data input possibilities. This would not be possible with a random copy of the production database or manually created spreadsheet data.
The user ID can be queried from the production database and blended with synthetic account numbers to ensure accurate, valid data. Transaction data can be synthetically generated with rules that control how sales tax is calculated based on location and the reward points applied based on size of purchase. This controlled data can be used to test assertions for validating the business logic and the accuracy of calculations.
Finally, intelligent test data can be generated in any volume from thousands of rows to billions of rows with a synthetic test data generation engine that operates at 10,000 rows per second. This level of intelligent test data provisioning enables true self-service and represents the future of intelligent automation.
Test Automation Becomes Intelligent Automation

The intelligent test data provisioning model described above is the missing ingredient for today’s test automation tools. Pairing these state-of-the-art tools with a cumbersome TDM system or with manual data creation degrades their efficiency and dilutes their value. When they are integrated with GenRocket’s Test Data Automation platform, test automation becomes intelligent automation.
This new combination makes perfect sense. As testers move to automation, they break down the application testing challenge into simple concerns that form the basis for each test case. At that point they have a well-defined testing objective and a corresponding test data requirement to validate the assertions. This is the perfect time to translate the test data challenge into a set of instructions for generating the data on-demand, with any variation of data, in any volume and using a valid data structure that ensures referential integrity.
With Test Data Automation, QA teams can now combine the power of automation with the intelligence of controlled data-driven testing to achieve quality at speed.
This concludes part 1 of our series on making the transition to intelligent automation. This edition makes the case for intelligent test data provisioning and lays the groundwork for future articles that will build on this concept. Stay tuned for the part 2 in the series as we progress through examples of intelligent automation by explaining GenRocket features and functions through real-world examples.
In the meantime, if you would like to learn more, request a live demonstration based on your own test automation environment.