Unstructured Data Accelerator (UDA): Bridging Intelligent Document Processing with Design-Driven Synthetic Data Generation
The Growing Challenge of Unstructured Data
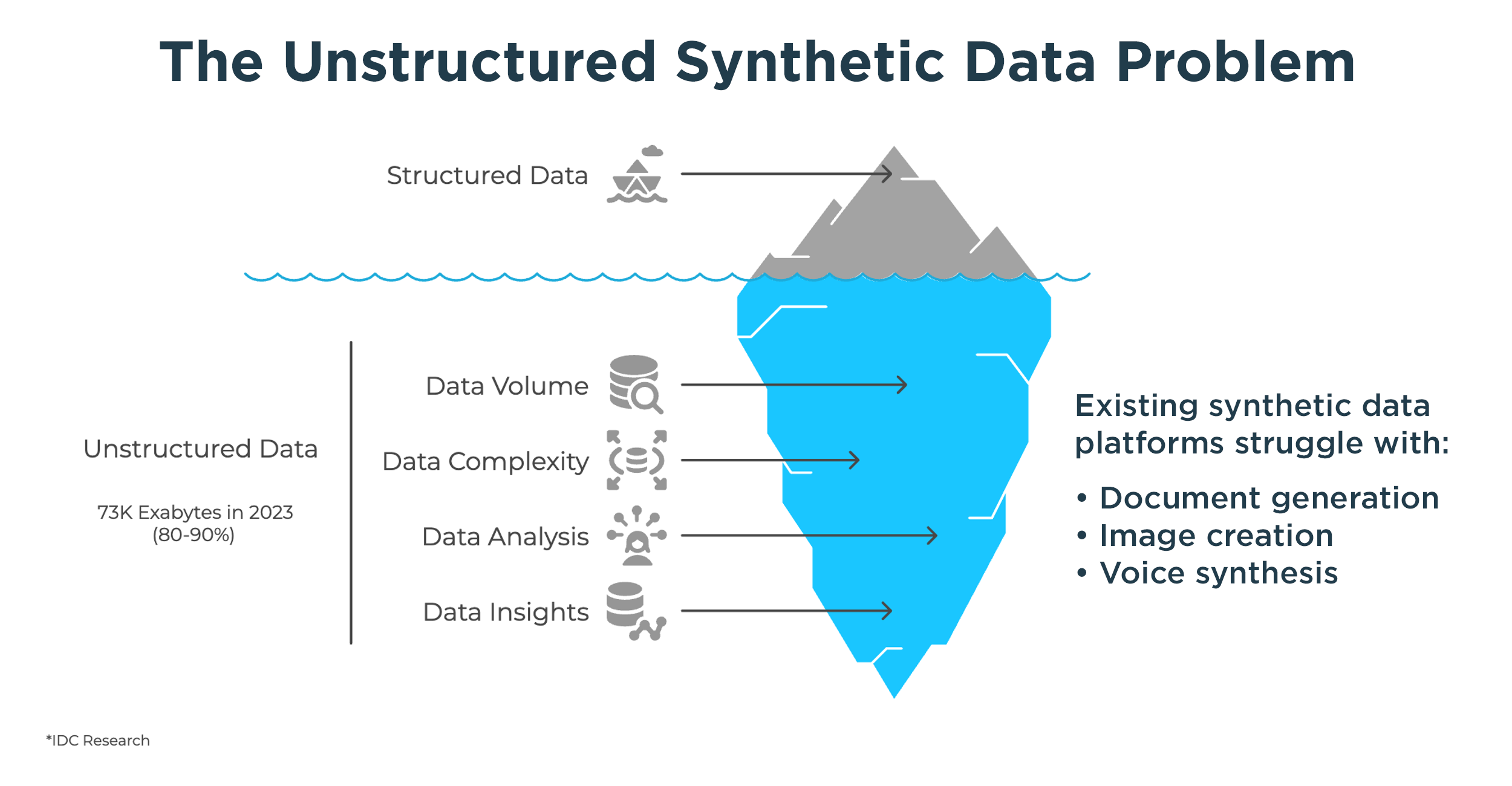
Most organizations process thousands of documents every day — forms, PDFs, images, and scanned records. These documents drive critical operations across industries such as banking, healthcare, insurance, and manufacturing.
According to IDC, 90% of enterprise data is unstructured. (Source: IDC, Sept 2024)
This unstructured information is hard to test, automate, and manage. It lives inside PDFs, handwritten forms, ID cards, or image attachments — data that is essential but difficult to validate or reproduce safely for testing and AI training.
In today’s digital enterprise, document-based workflows — applications, claims, contracts, and approvals — are everywhere. The challenge isn’t just capturing data; it’s ensuring that it remains complete, accurate, and traceable across every process.
That’s why we built GenRocket’s Unstructured Data Accelerator (UDA) — to help enterprises automate, validate, and manage unstructured data with referential integrity. The Unstructured Data Accelerator transforms unstructured content into a consistent, trusted data asset.
The Missing Link in Document Automation: Why UDA Matters for Data Integrity
Document processing has evolved well beyond scanning and OCR. Traditional systems convert physical content into digital form, while modern Intelligent Document Processing (IDP) uses AI and machine learning to interpret both structured and unstructured data (IBM: Document Processing Overview).
According to Fortune Business Insights, the global IDP market will grow from US $7.89 billion in 2024 to US $66.68 billion by 2032, a 30% CAGR. Yet a SER Group survey shows that 65% of organizations plan new IDP projects while 61% still depend on paper, and nearly half expect paper use to increase.
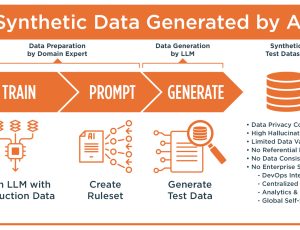
Automation has advanced, but testing and validating document workflows remain largely manual. The Unstructured Data Accelerator (UDA) fills that gap by introducing design-driven synthetic data generation — ensuring that documents and the data within them can be tested, validated, and trusted across diverse, interconnected systems.
How the Unstructured Data Accelerator Works
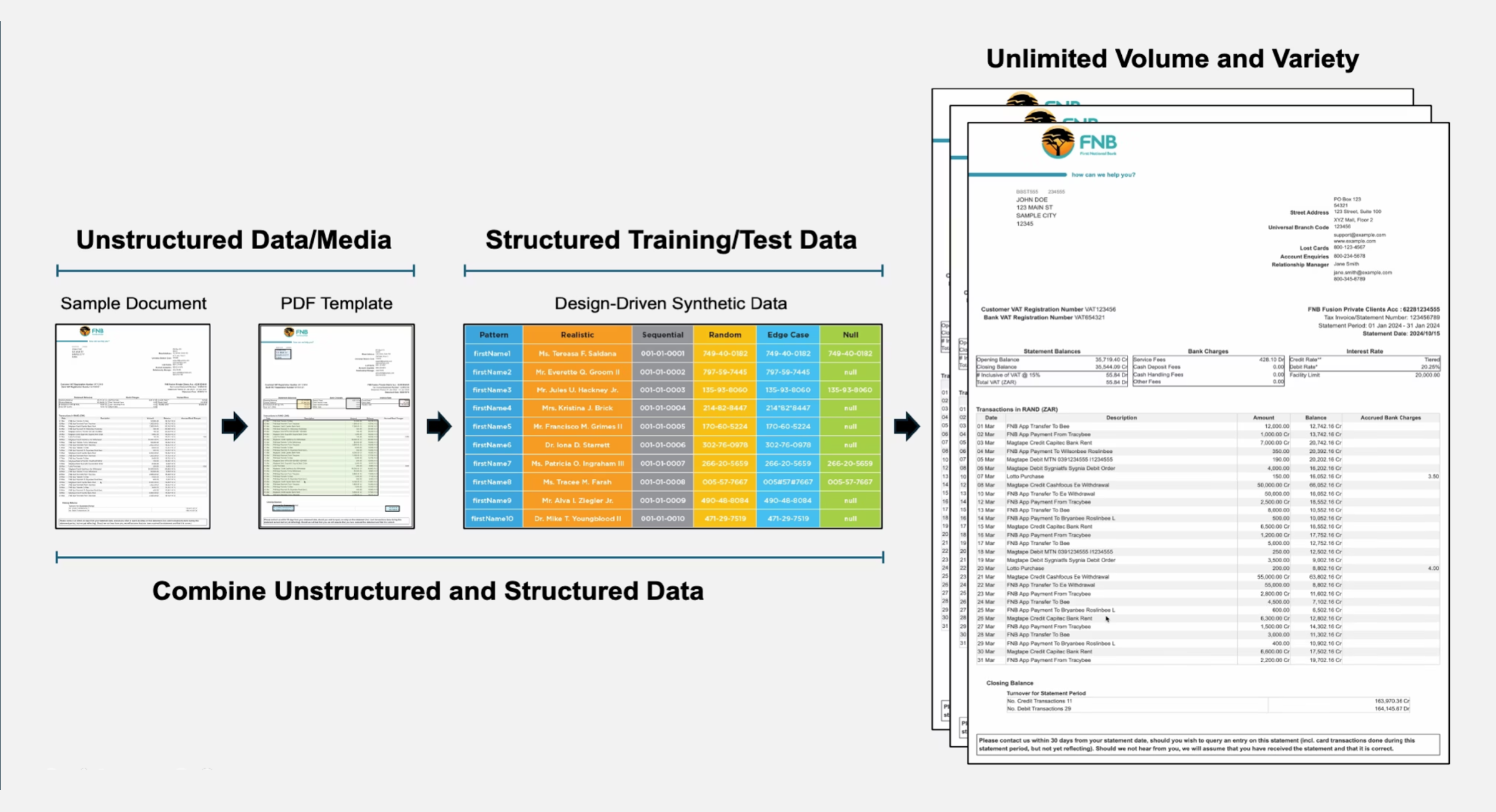
The Unstructured Data Accelerator (UDA) extends GenRocket’s Synthetic Data Platform to include documents, images and other unstructured media.
With UDA, teams can:
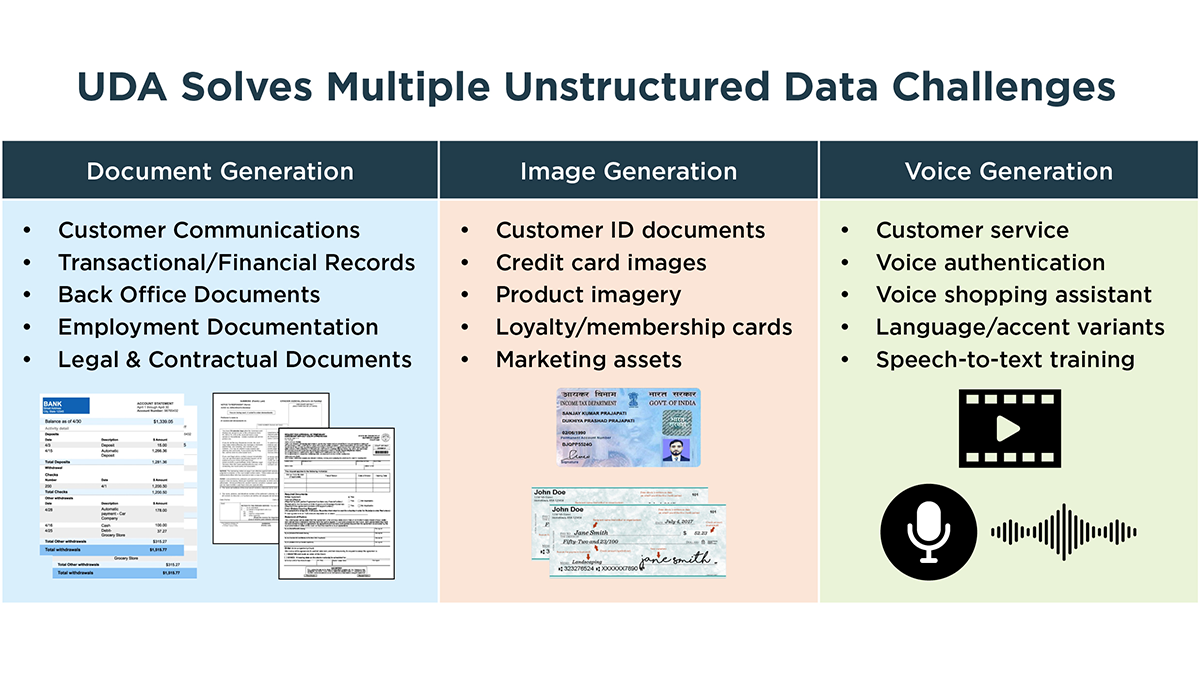
- Generate realistic, privacy compliant document data — such as invoices, statements, claims, contracts, IDs.
- Preserve referential integrity between large volumes of unstructured documents containing structured data elements.
- Simulate positive and negative scenarios — missing signatures, blurred scans, handwritten entries, or torn pages.
- Support downstream testing, AI training, and compliance workflows that rely on accurate document data.
Together, these capabilities bridge Intelligent Document Processing (IDP) and synthetic data generation — giving document-centric systems both the data needed for comprehensive testing and training to ensure applications perform reliably at scale.
Industry Use Cases That Bring UDA to Life
The Unstructured Data Accelerator delivers measurable value in industries where document accuracy, privacy, and compliance are essential.
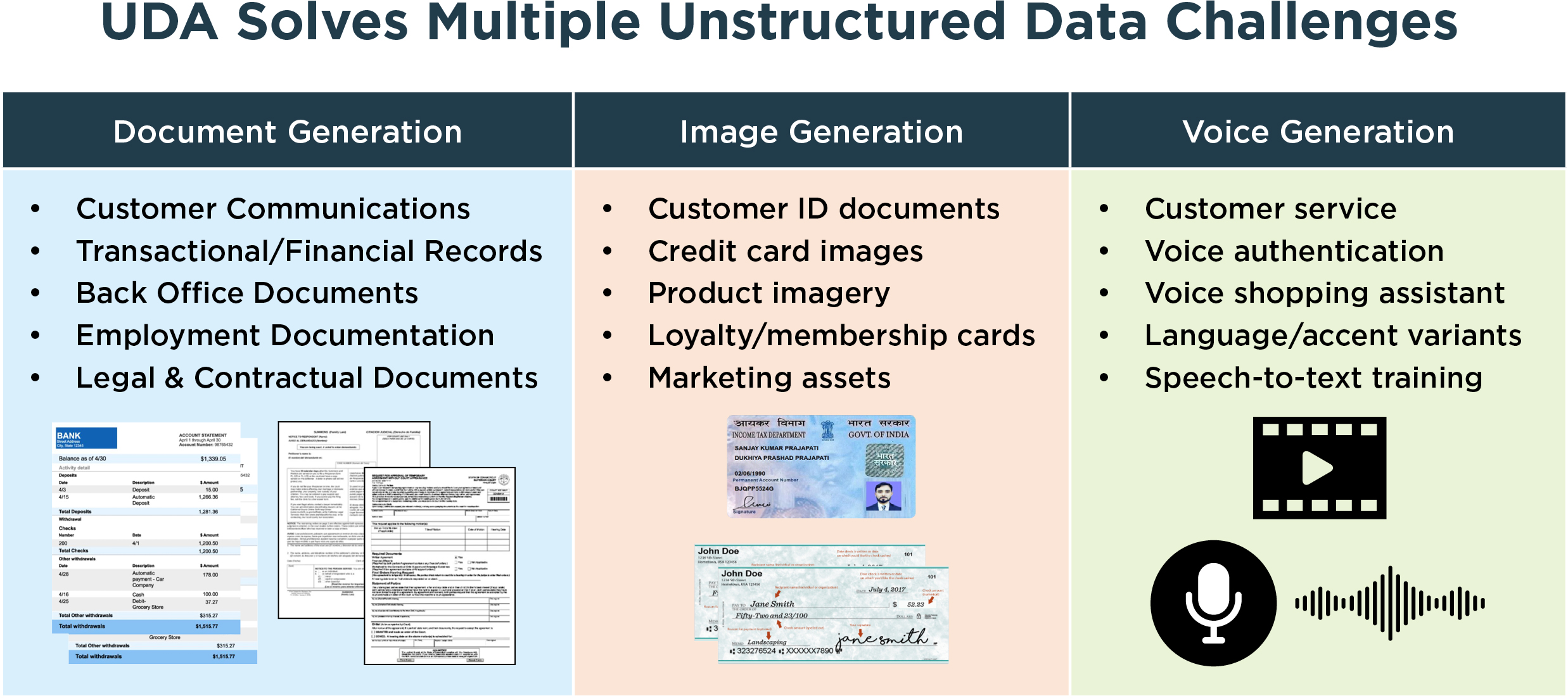
Financial Services & Insurance
Loan applications, claims forms, and statements combine structured data (customer IDs, account numbers) with document layouts and images.

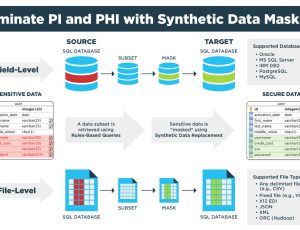
With the Unstructured Data Accelerator, banks and insurers can create synthetic, realistic versions of these documents — complete with stamps, watermarks, and handwriting variations — while preserving ldata accuracy, completeness and referential integrity between every form field.
Healthcare & Life Sciences
Hospitals and labs handle scanned test orders, lab results, and insurance claims every day. UDA reproduces these documents with controlled negative testing variations — blurred scans, missing data, or inconsistent handwriting — along with controlled and conditioned tabular data enabling QA and AI teams to validate system behaviour safely and in compliance with healthcare privacy regulations.

Operations & Back-Office Processes
Enterprises rely on documents such as purchase orders, contracts, and timesheets. The Unstructured Data Accelerator can generate consistent, compliant versions of these assets, supporting workflow automation and ensuring data accuracy across enterprise systems.
Designed for Testing, Training, and Continuous Validation
QA and testing teams use UDA to generate large sets of realistic documents for regression, performance, and edge-case testing. What once took days and weeks of collecting and sanitizing data can now be done in hours, with full control over volume and variety.
AI data engineering teams use it to create privacy-safe training data for document classification, OCR, or NLP models — without relying on sensitive production records or manual data creation.
In short, the Unstructured Data Accelerator gives every team that works with documents a shared advantage: access to reliable, realistic data they can test, train, and trust. Built on GenRocket’s patented referential integrity capabilities, every document generated through UDA contains accurate and secure synthetic data fully integrated across development, testing, and CI/CD workflows.
Why GenRocket’s Approach Is Different
- Design-Driven Data – Every data element and document is rule-based and tailored for each test case objective.
- End-to-End Integrity – Structured and unstructured data remain controlled and referentially intact throughout workflows.
- Scalable and Secure – Synthetic data is generated and delivered on demand without exposing sensitive production information.
- Industry-Specific Templates – GenRocket allows you to build reusable PDF and image templates for any number of use cases in banking, insurance, and healthcare.
The Unstructured Data Accelerator extends GenRocket’s Quality Evolution Platform (QEP), applying the same precision used for database and API data to documents, images, and media.

From Automation to Assurance: The Enterprise Impact of UDA
The true value of the Unstructured Data Accelerator (UDA) becomes clear when enterprises begin to measure what it changes — not just in efficiency, but in reliability and accuracy across their data-driven workflows.
- Reduced cost and time in document-based testing and automation
Traditional document testing is slow because it depends on collecting, cleaning, and anonymizing production data. With UDA, teams can generate an unlimited volume of realistic, production-safe documents in hours instead of weeks. Test coverage expands dramatically, release cycles shorten, and QA teams spend less time provisioning data and more time ensuring quality. - Improved accuracy in OCR and AI document recognition
Machine-learning and OCR systems are only as good as the data they see. UDA lets data-science teams train models on diverse, representative document sets — including imperfect samples such as blurred scans or incomplete forms. This improves recognition accuracy and model accuracy without exposing real customer information. - Ensured compliance with privacy and data-protection standards
UDA is designed for environments where privacy is non-negotiable. All data is generated synthetically and on demand, maintaining full referential integrity while keeping regulated data sources untouched. This allows organizations to meet requirements under HIPAA, GDPR, and other global privacy frameworks with confidence.
By integrating UDA into the GenRocket Design-Driven Synthetic Data Platform, enterprises gain more than automation — they gain data they can trust to power development, testing, and AI innovation at scale.
How to Get Started
- Identify a document-intensive process in your organization — such as claims, onboarding, or invoicing.
- Engage with the GenRocket team for a UDA discovery discussion.
- Request a proof of concept using your document formats and workflows.
The Unstructured Data Accelerator (UDA) is now part of the GenRocket Design-Driven Synthetic Data Platform, helping enterprises bridge the gap between unstructured and structured synthetic data for testing and training intelligent document processing systems at scale.