Reimagining Healthcare Through Synthetic Data
Healthcare organizations are under constant demand to innovate—modernize legacy systems, adopt AI, and improve interoperability—while operating under some of the strictest data privacy regulations of any industry.
The challenge isn’t a lack of data.
It’s a lack of usable, compliant, and scalable data.
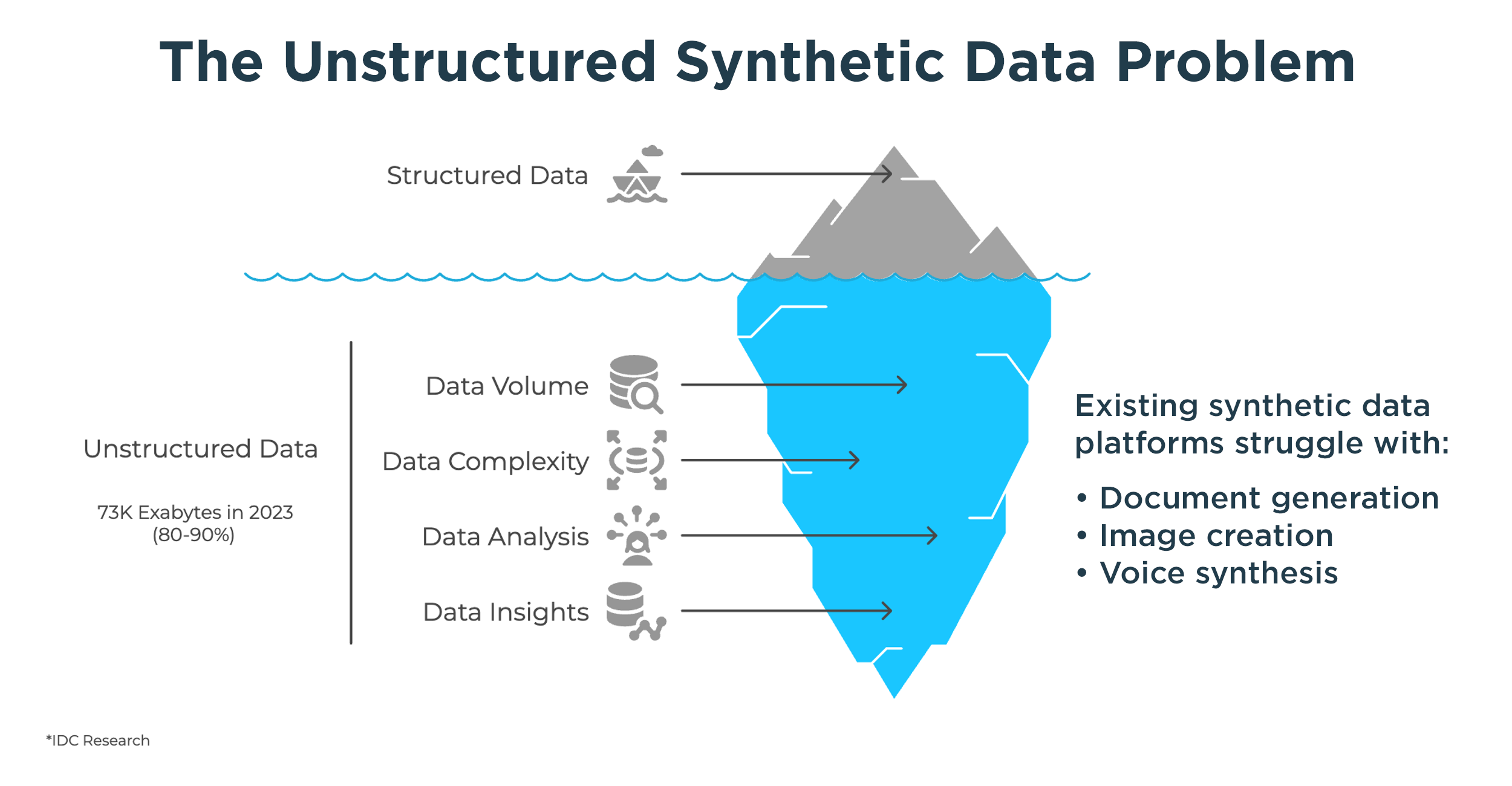
Industry research consistently shows that the majority of healthcare data is sensitive and unstructured, making it difficult to access and risky to use. IBM and other analysts estimate that up to 80% of healthcare data is unstructured, including clinical notes, documents, images, and voice data—much of it containing patient-identifiable information.
This reality turns data into a bottleneck rather than an accelerator.
That’s why synthetic data is becoming foundational to healthcare innovation.
In this article, we explore why unstructured data has become such a critical challenge in healthcare—and how design-driven synthetic data is helping organizations move forward safely and at scale. These themes were also discussed in depth on the Shaping Healthcare podcast episode, “Reimagining Healthcare through Synthetic Data Advancements.”
The episode is available on Apple Podcasts, Spotify, and YouTube.
Why Synthetic Data Works for Healthcare
Synthetic data isn’t anonymized or masked production data. It’s designed data—generated from metadata, rules, and intent rather than real patient records.
When implemented correctly, synthetic data enables healthcare organizations to:
- Eliminate privacy risk entirely by avoiding production data access
- Achieve near-100% test coverage, including edge cases and negative scenarios rarely found in real datasets
- Train AI/ML models using balanced, unbiased data
- Scale data volume instantly for performance, load, and regression testing
- Shift testing and validation earlier in the SDLC—without waiting on data provisioning
For healthcare teams, this translates into faster delivery, higher-quality systems, and compliance by design—not as an afterthought.
From Traditional TDM to Design-Driven Synthetic Data
Historically, healthcare organizations relied on traditional Test Data Management (TDM)—extracting production data, masking sensitive fields, and managing copies across environments.
That approach worked when:
- Sources of quality synthetic data were limited
- Teams were willing to augment production data manually
- Data privacy laws were less stringent
Today, it breaks down.
Masking still requires access to sensitive production data. Coverage remains limited to historical data patterns. Rare conditions, edge cases, and negative scenarios are difficult to reproduce. And privacy risk is reduced—but never fully eliminated.
Design-driven synthetic data represents the next step in that evolution:
- No production data access is required
- No reverse-engineerable masking logic
- Full control over data volume, variety, and format

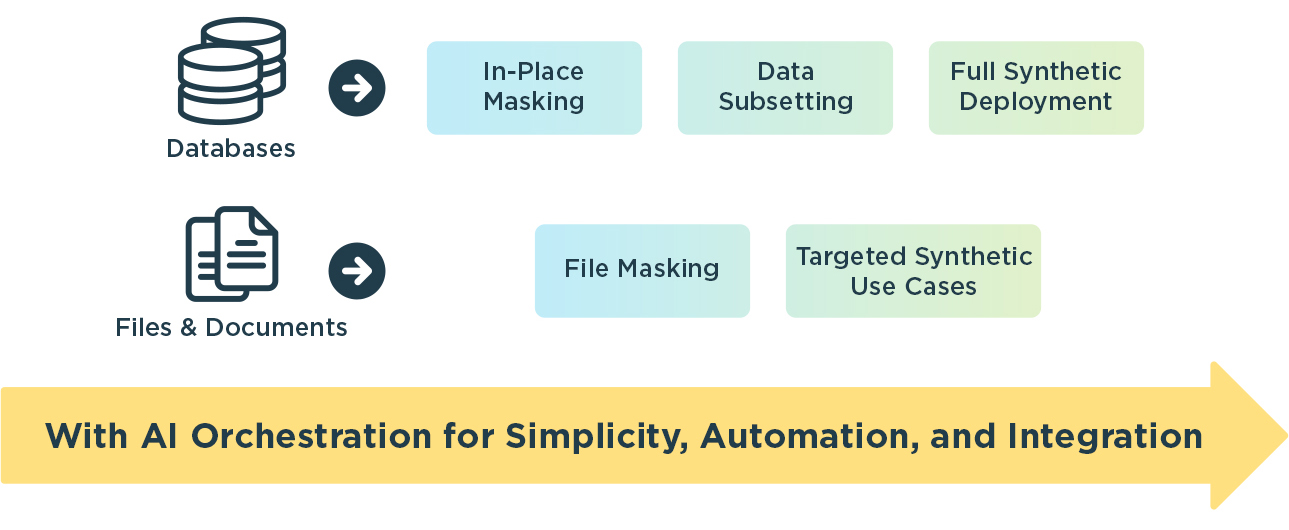
This evolution isn’t just about better data—it’s about quality, efficiency, and privacy by design. Traditional TDM introduces friction across the SDLC through long provisioning cycles, incomplete datasets, and brittle masking processes that slow testing and limit coverage. Design-driven synthetic data removes those constraints. Quality Engineering teams gain deterministic, repeatable datasets that can be regenerated on demand across environments—supporting full regression testing, parallel system validation, and CI/CD automation. At the same time, privacy risk is eliminated rather than mitigated, because production data is never accessed.
It’s not a replacement overnight—it’s a bridge from legacy TDM to a future-ready healthcare data strategy.
Why Quality Engineering Demands Synthetic Data
Healthcare systems aren’t just built—they’re continuously improved and validated.
Claims platforms, clinical systems, and payer workflows operate in highly regulated environments where even small defects can have financial, clinical, or compliance consequences. As systems evolve, Quality Engineering teams are expected to validate changes faster, more frequently, and with greater confidence.
That requires a new level of data quality.
Modern healthcare QE depends on:
- Deterministic, repeatable datasets that behave the same way every time
- Parallel testing across legacy and modernized systems to ensure functional parity
- Full regression coverage with every release—not partial sampling
- Auditability and traceability to prove what was tested, when, and with which data
Traditional approaches—manual test data creation, masked production extracts, or one-off scripts—struggle to meet these requirements at scale.
Synthetic data changes the equation.
With design-driven synthetic data, Quality Engineering teams can:
- Generate the exact same dataset across environments and test cycles
- Validate system behavior under both real-world and worst-case conditions, including rare and negative scenarios
- Shift testing left, enabling validation earlier in the SDLC rather than waiting for production-like data
- Test more frequently and at greater scale, without data provisioning bottlenecks
Support CI/CD pipelines with embedded, on-demand data delivery
Just as importantly, synthetic data improves risk posture. Because no sensitive production data is used, QE teams can test aggressively without introducing privacy exposure—while still maintaining referential integrity and business logic accuracy.
For healthcare QE teams, synthetic data isn’t just faster.It brings higher quality, operational efficiency and absolute data privacy—making it a foundational capability for modern healthcare delivery.
Why Unstructured Data Is the Next Healthcare Data Frontier
Healthcare data extends far beyond rows and columns of database tables.
Clinical notes, claims forms, scanned documents, images, and voice interactions are central to care delivery and operations—but are among the hardest data assets to use safely.
Today, unstructured synthetic data is changing that with the help of GenRocket’s Unstructured Data Accelerator (UDA).
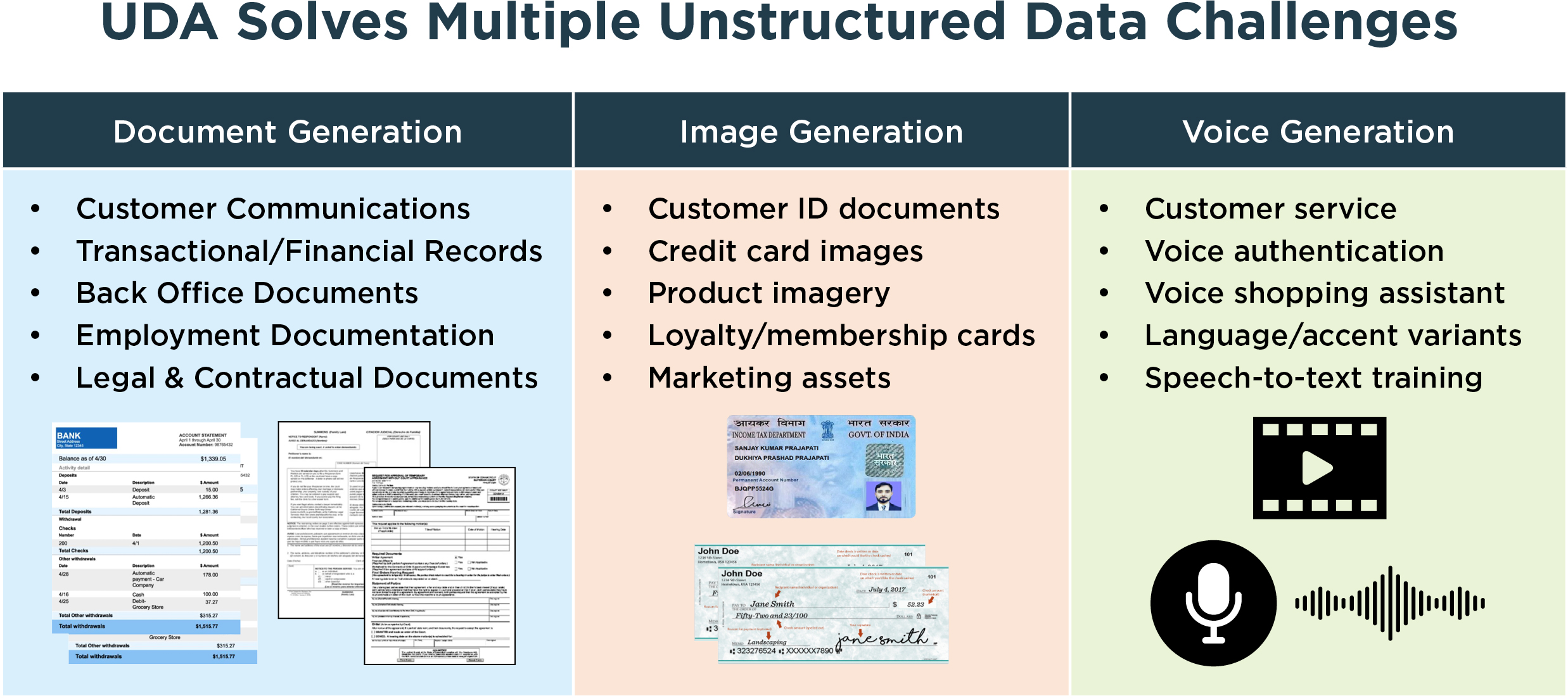
Synthetic documents, images, and voice data can now be generated with realism, variability, and intent—supporting:
- Intelligent document processing
- AI-driven automation
- Conversational and voice-based systems
- End-to-end workflow testing without exposing real patient artifacts
This allows healthcare organizations to modernize workflows and train AI systems without relying on real patient data at any stage.
Synthetic Data in Action: Real-World Healthcare Use Cases
These topics were explored in depth on the Shaping Healthcare podcast episode:
🎙️ “Reimagining Healthcare through Synthetic Data Advancements”
The conversation examines how healthcare organizations are applying synthetic data across application testing, interoperability validation, AI/ML training, and unstructured data workflows—and why synthetic data has evolved from a point solution into a core enabler of healthcare modernization.
For leaders responsible for healthcare platforms, data engineering, quality assurance, or AI initiatives, the episode offers practical insight into how teams are scaling innovation while maintaining privacy, compliance, and operational velocity.
Listen to the episode on your preferred platform:
Apple Podcasts | Spotify | YouTube
Advancing Healthcare Innovation Through Collaboration
We thank CitiusTech for hosting Shaping Healthcare and enabling conversations grounded in execution and outcomes. Special appreciation to our CEO and co-founder Mr. Garth Rose and Gaurav Shrimal, AVP CitiusTech for sharing applied perspectives on how synthetic data is driving measurable impact across healthcare systems today.
As healthcare continues to modernize, success will depend on the ability to innovate safely, at scale, and with confidence.
Design-driven synthetic data makes that possible—by design.